一说起日志系统,大家一定想到了ELK(efk)那一套,,其实还有一个叫Graylog的…
Graylog工作流程

Graylog 架构
Deep Workflow
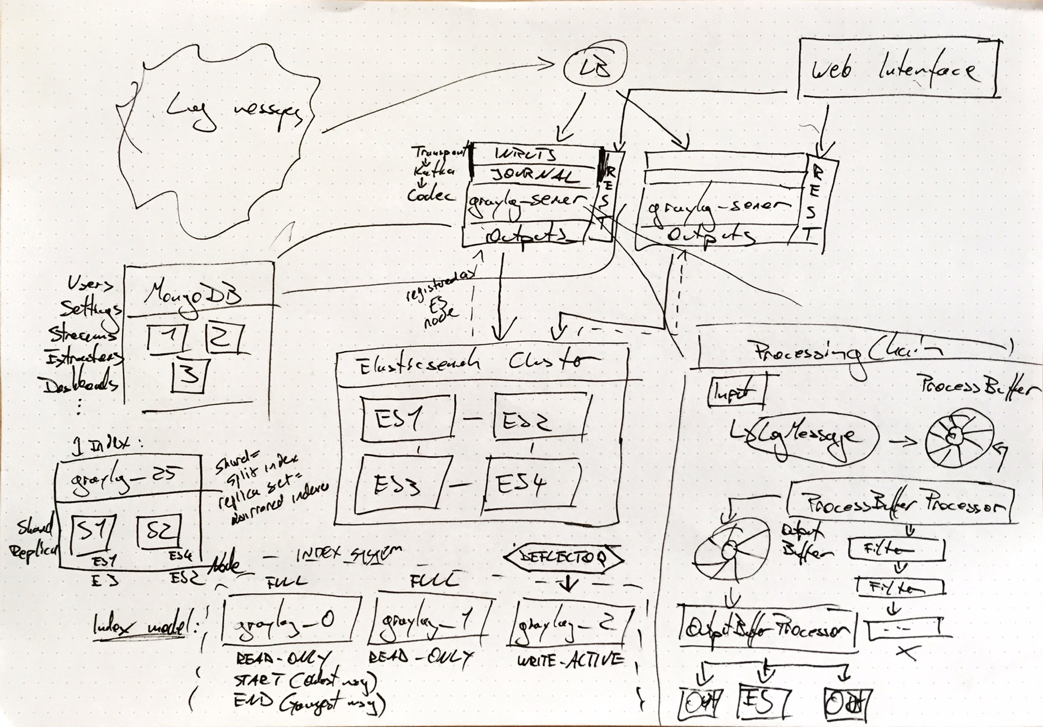
工作流草图
Log messages source & LB
基本上,可以接受任何机器的数据(结构化或非结构化),并使用喜欢的任何负载均衡器。 消息的数量,其峰值率,平均大小和提取将影响性能。
Transport Layer
这是Graylog服务器上的输入和日志。内部处理使用的Kafka的代码。
Processing Chain
将这些消息取出并写入进程缓冲区,这是一个环形的缓冲区。然后,进程缓冲处理器处理消息,其中发生流路由和提取字段。 这部分处理时,过滤后的消息然后进入输出缓冲区(另一个环形缓冲区),然后进入输出缓冲区处理器,然后进入Elasticsearch(ES)或用户定义的输出。(提示:调整每个缓冲区运行的处理器数量很重要,不应超过可用于graylog-server的CPU内核数量。增加处理器数量,如果您看到过低的吞吐量,并尝试专注于处理缓冲区处理器,因为输出缓冲区通常不需要很多。)
REST API
Web前端使用的API
MONGODB
它只存储元数据:所有项目的用户,设置和配置数据:流,仪表板,提取器等。您配置的一切内容。如果Mongo宕机挂掉了,Graylog将继续运行。因此,如过我们使用过程选择将其纳入高可用性设计。可以选择 Mongo的HA场景 三个实例。关键词Mongo Replication set。
Elasticsearch Cluster
这里看起来像一个ES节点,并且了解每个ES服务器的配置数据(索引,分片等)。对于HA,建议至少配置一个副本。
Anatomy of an Index(索引解析)
单个索引(在上图中,Graylog Index#25)被分解成碎片。这意味着索引被分解,部件在不同的ES节点上运行。这样可以更快地进行搜索,因为可以在多个ES节点上并行计算查询结果。索引也可以配置副本。这意味着每个分片都被镜像到其他节点,对于HA是非常好的。
Index Model
每个索引首次从0开始编号。在时间序列数据库中,所有数据都以时间戳存储,一旦存储就不会被重写(因此标记为READ_ONLY对于WRITE_ACTIVE表现)。所以,消息不会被重新插入。这使的它很快。由于基于时间的存储,这也意味着当查询时,必须给出时间限制搜索(即在最后一小时内)。 (提示:所以这些索引的大小在性能调优时很重要。你不想使索引太大,因为搜索将需要更长的时间,并且你不希望它们太短,因为同样的原因。索引的大小应根据您拥有的数据量以及通常搜索的程度而定。有时候,人们将它用于较长的历史战略类型搜索。了解并确定尺寸是非常重要的。备注:ES集群都会存在搜索,索引太大导致时间拉长。)
Deflector(变流装置,我的理解就像nginx日志切割一样,不会影响下一个文件的写入)
原作者写入一个可以被原子性的切换到新索引的被称为“Deflector / 偏转器”的索引别名。这样我们就不必担心在创建新的索引时停止消息处理,因为这样很容易被管理(如:索引#25现在已经关闭了啊等等,接下来的一个是#26,继续写)。
二、支持的消息输入源
Syslog
支持RFC 5424和RFC 3164兼容的syslog消息,TCP和UDP传输日志。另外,许多设备,特别是路由器和防火墙,不发送符合RFC的syslog消息,这个时候不得不使用原始/纯文本消息输入的组合。
GELF / Sending from applications
Graylog扩展日志格式(GELF)是一种日志格式,可以避免经典的纯系统日志的缺点,非常适合从应用层记录。它具有可选的压缩,分块和最重要的是一个明确定义的结构。 也可以通过HTTP发送所有GELF类型,包括只是纯JSON字符串的未压缩GELF。
Using Apache Kafka as transport queue
使用apache 的 Kafka 作为传输队列。
Using RabbitMQ (AMQP) as transport queue
使用RabbitMQ 作为传输队列
Ruby on Rails 在Gemfile 文件中添加以下内容
gem "gelf"
gem "lograge"Raw/Plaintext inputs
内置的原始/纯文本输入允许您解析可以通过TCP或UDP发送任何文本。 如果需要极高的灵活性,还可以编写插件。
Reading from files
Collector Sidecar,它作为其他程序(如nxlog和Filebeats)的主管进程,这些程序专门用于从本地文件收集日志消息并将其发送到像Graylog这样的远程系统。 也可以使用支持GELF或syslog协议(包括其他)的任何程序将您的日志发送到Graylog。
三、最小安装架构
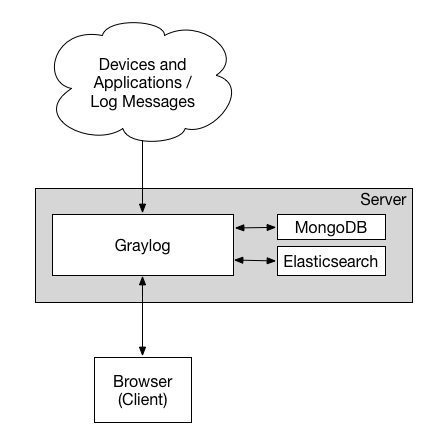
最小安装(不推荐生产环境)
各组件功能:
- MongoDB 用于存储配置元信息和配置数据(无需太多硬件资源配置)
- Elasticsearch 用于存储日志数据(内存大以及更高的磁盘IO)
- Graylog 用于读取日志、展示日志。(CPU密集)
缺点:
- 系统无冗余、容易出现单点故障,适合测试阶段
四、大型生产环境架构

生产安装
相比最小架构来说,以下是变化部分:
- 客户访问和日志源面对的是前端的LB,LB通过Graylog REST API 负载管理Graylog集群
- Elasticsearch 使用集群方案,多节点存储数据,达到备份冗余、负载的效应
- MongoDB 集群,具备自动的容错功能(auto-failover),自动恢复的(auto-recovery)的高可用
- 各组件方便伸缩扩展