最近做了一下公司容器集群日志的收集方案架构…
一、初步架构图
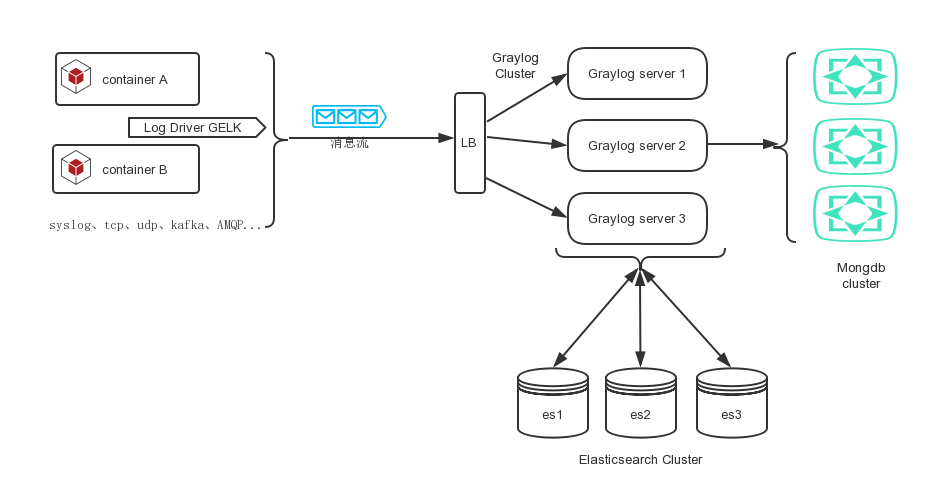
容器日志系统
- docker 日志通过docker的日志驱动GELK,将日志输出到LB处。
- LB 可以用haproxy、nginx。用于负载Graylog server集群。
- Gaylog cluster 用于接收消息的输入、通过Grok 表达式来对日志进行分段。并将数据存入es中。
- Mongdb Cluster只存储元数据:所有项目的用户,设置和配置数据:流,仪表板,提取器等其它配置的一切内容。如果Mongo宕机挂掉了,Graylog将继续运行。
- Elasticsearch Cluster 用于存储消息。
二、预期目标
- 收集每个docker 容器的应用日志
- 对日志进行聚合分析
- 可以满足后期对主机系统日志、操作审计日志的收集需要
三、待改进
支持Kafka 消息缓冲的架构
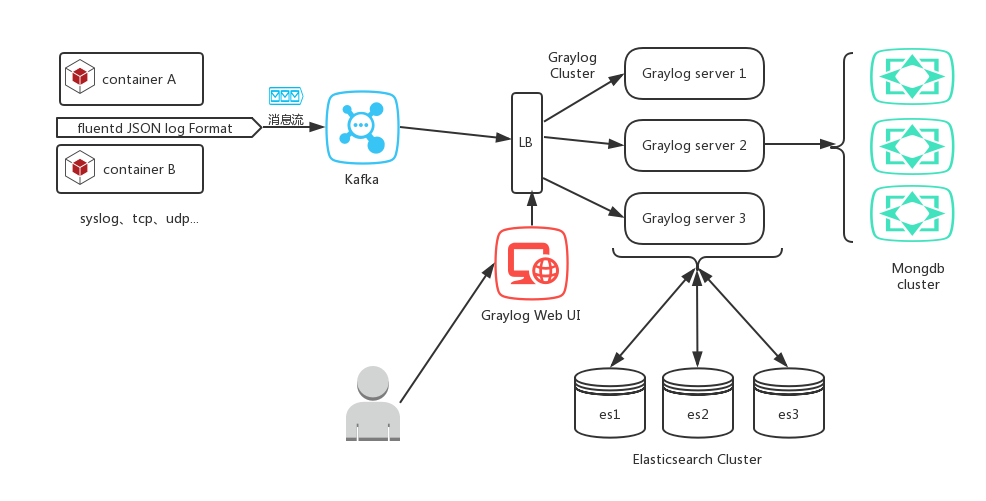
容器日志系统
Notes:在fluentd 处也可在docker最新版本中使用开源docker log driver to kafka 的插件替换。
项目地址:https://github.com/MickayG/moby-kafka-logdriver
四、原docker引擎配置修改
有2种方式:
1.Docker 容器启动时,需添加 --log-driver=gelf --log-opt gelf-address=x.x.x.x 参数.
2.fluentd daemon方式:在每个docker主机上启动一个fluentd容器,之后在启动其它相关应用时,使用--log-driver... ,该日志记录驱动程序将尝试查找本地Fluentd容器监听TCP端口24224上的连接。
五、需关注的功能
- 过滤特殊敏感字段
- debug日志多行方式如何收集?